I know that I’d promised to have a further look at AWS CDK and CDK Pipelines – I must confess I haven’t managed to finish what I had planned to do; time has also been a bit of an issue during lockdown v2. Meanwhile I thought I’d write a post that I’d been meaning to create for a while.
Recently we had a situation where we needed to copy a large amount of data from a DynamoDB table into another one in a different account. Originally we used a Scan function to get items with a ExclusiveStartKey/LastEvaluatedKey marker to check if more records needed to be obtained. Then we used PutItem API call to insert data into the destination table. Because there were several hundred thousand records in the table, it took several hours to copy them; at that point we decided that we needed to use a faster method to copy the data. We achieved a massive improvement of the copying times by using Parallel Scans and Writing Items in Batch. This post will provide an example of how to use them and compare the results of the methods we used.
For demo purposes, I’m using the same account, rather than different ones. I have written a method to create a simple DynamoDB table programmatically. It will contain data about temperatures in 2020 in a few cities:
I use the method above to create several tables (and also wait to ensure the table I need to populate first has been created):
Then I populate the source table with some data about temperatures:
A side note on things learnt when trying to create a table: when you create a table programmatically, you only need to specify only those AttributeDefinitions that are going to be used as partition key/sort key. I had originally wanted to put all the four Attribute Definitions (City, Date, Highest, Lowest) at the table creation stage, but the program was throwing an error about KeySchema not having the same number of elements as AttributeDefinitions.
Now, the most interesting part starts. First, I call a method to copy the data slowly. I use Scan and PutItem API calls.
Since the demo database only has 100 items, I’m not using ExclusiveStartKey/LastEvaluatedKey with the Scan operation; those are definitely necessary for large tables as Scan only gets maximum of 1MB of data.
I then call another method to copy data using Parallel Scans. I specify how many parallel worker threads I want to create by using totalSegments variable. In this case it was set to 3, but you can probably have as many as you like):
While simple Scan accesses one partition at a time, when using Parallel Scans several worker threads are created, and each of them scans a certain segment of the table. BatchWriteItem operation allows you to create a PutItem request for up to 25 items at a time.
As a result, the difference in copying speed is noticeable:
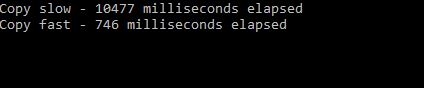
Another point to mention is that this task has been helpful in preparation for the AWS Developer Associate exam (I haven’t taken it yet though)– there were a couple of questions where the correct answers were ‘Parallel Scans’ and ‘BatchWriteItem’, and I was very happy that I had come across this scenario at work!
Happy learning!